我们身边的大数据
您是否经常有这样的经历:不小心在“今日头条”点开了某明星的八卦新闻,然后接下来刷到的都是“八卦类”资讯;刚在京东搜索过某型号笔记本电脑,结果微信公众号文章下面的广告都变成了笔记本电脑;到过高风险地区,自己还未到社区申报,健康码就变成了红色;导航软件对于路线拥堵长度以及通过时长的预测几乎分秒不差……这一切背后的都是大数据在发挥作用。
在年初的疫情防控工作中,大数据在疫情态势分析、传播模型推演方面起到了至关重要的作用。全民热议的“火神山”建设也用到了大数据技术,数据平台“一声令下”,火神山周边数百台混凝土泵车、汽车吊、挖掘机和推土机等设备赶到现场,并有序受领工作任务。
大数据甚至还能够帮助候选人赢得“总统大选”。据报道,一家名叫Cambridge Analytica的数据分析公司使用大数据和AI分析Facebook用户资料,操纵舆论帮助特朗普赢得了大选。
但是,您知道我们国家的大数据“选官”吗?
早在2014年,全国各地就开始探索以建立数据库的方式考核、管理和选拔使用干部。笔者以“选人用人”和“大数据”为关键词利用百度搜索引擎进行检索,经过人工筛选后,共梳理出涉及不同地方的相关新闻报道47例。具体情况分析如下。
1、大数据“选官”概况
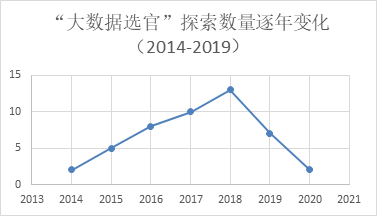
图1 各地“大数据选官”探索的数量变化(2014-2019)
随着信息技术的不断发展,全国各地自2014年开始尝试使用大数据管理、监督和选拔干部,且呈逐年递增之势。仅2018年一年就有13个地方开展这方面的探索。大概是意识到地方政府数据平台重复建设问题严重,自2019年数量开始呈现下降趋势。
从城市级别上来看,47个地方中设区的市有10个,区县(旗)35个,国家级新区2个,区县级城市创新的动力和需求明显高于设区的市,数量是后者的三倍多(见表1)。
表1 探索“大数据选官”的城市级别
城市级别 | 数量 | 占比 |
设区的市 | 10 | 21.27% |
国家新区 | 2 | 4.26% |
区县(旗) | 35 | 74.47% |
总计 | 47 | 100% |
从这些地方所处的地理位置来看,东南沿海城市的数量明显要高于中西部地区。但湖南、云南、贵州三个中西部省份占据了排名前5的3个(见表2),排名顺序大致与三个省份的人口数量呈现出一种正相关关系。在实施干部大数据平台建设的单位类型中,党委组织部门占据了绝大多数,纪委监委主导的大数据平台建设只占一小部分。
表2 探索“大数据选官”城市的省份分布
省份 | 数量 | 省份 | 数量 |
山东 | 5 | 湖北 | 2 |
湖南 | 5 | 河南 | 1 |
云南 | 5 | 四川 | 1 |
江苏 | 4 | 江西 | 1 |
贵州 | 4 | 吉林 | 1 |
广西 | 3 | 辽宁 | 1 |
浙江 | 3 | 内蒙古 | 1 |
甘肃 | 3 | 陕西 | 1 |
上海 | 2 | 广东 | 1 |
宁夏 | 2 | 福建 | 1 |
2、大数据“选官”用到了哪些数据
从各地所利用的数据来源上,我们大致可以将其分为三类:
第一类是利用干部个人信息、考核信息、奖惩信息、财产申报信息、教育培训信息、工作履历信息、民主测评信息、领导班子搭配情况等组织部门已经掌握的历史数据进行建库,也可以概括为“纸转电”(纸质档案的电子化)。
第二类是在上述基础上增加了组织部门创新管理所带来的新数据信息,包括考勤信息、车辆位置信息、常态化的民主测评(积分)信息、重点领域工作表现、邻里风评、个人发展意愿、干部工作日志等等。镇江新区建设的“新区干部综合分析研判系统”,结合重点项目信息的挖掘、跟踪、落户、筹建、投产达效、生产经营的数据,对研判对象的工作量、工作成效和工作成本进行实绩分析。
第三类是引入了其他职能部门掌握的大数据信息,包括纪检监察、信访、审计、人社等职能部门干部监督信息,以及公安、检察、法院、社保(征信)、统计、扶贫、环保、安监、出入境等大数据信息和不动产、机动车、股票、银行理财等财产登记信息。比如云南省新平县借力民生资金监管平台,动态监管全县各相关单位民生资金拨付、发放等管理使用情况和信息录入、发布情况。
3、大数据“选官”如何分析、运用数据
从数据分析的方法和用途上来看,
第一种做法是对大数据信息的直接统计分析使用,计算出干部各方面得分,将查询结果作为干部评优评先、提拔使用、班子成员调整的依据;
第二种做法是深度挖掘大数据信息的内在价值,构建大数据分析模型,借助大数据分析模型对领导干部进行全方位立体化的“政治画像”,从政治表现、性格特点、专业能力、工作作风、廉洁自律、群众评价、风格类型、熟悉领域、负面清单等多维度精准分析评价干部。浙江省温州市党委组织部门还构建“干部胜任力模型”,对人岗匹配程度进行科学分析。
4、大数据“选官”的发展态势
各地实践在总体上呈现出以下特点和趋势:
从单一数据来源转向跨部门数据整合;
唤醒历史“沉睡”数据与整合碎片数据相结合;
从正向评价转向正向评价和负面清单相结合;
从事后管理转向事中管理,甚至是事前管理;
从数据简单的统计分析转向复杂的大数据分析模型;
考核评价从过去的小范围、定时定点转向跨部门、多领域、常态化,并向八小时之外延伸。比如江苏省吴中区建立的“七位一体政绩考核指标体系”不仅关注领导班子年度考核测评结果,还综合纪委、农办等职能部门提供的重要经济社会发展统计大数据,建立涉及30多个部门的50多项考核指标;
对数据的利用从粗放式转向精细化、专业化,比如永州市委组织部建立的“干部管理大数据应用信息系统”,将干部选拔任用、干部考核管理、干部监督管理设立单独模块,相同的数据经过不同的计算模型分析处理后可以满足不同的使用场景。
5、大数据“选官”存在的问题
从整体上看,这些地方利用大数据选拔干部的探索为科学选人用人积累了有益经验,值得肯定,但仍然需要进一步总结和反思。
数据平台的多头建设问题。这其中既有组织部门主导的干部大数据建设,也有纪委监委和检察系统牵头主导的。不仅会造成资源浪费,还会出现“九龙治水”的乱象;
数据来源单一、各部门之间信息壁垒的问题。对领导干部的全面分析需要全面的数据作为有效支撑。大数据平台的建设需要对审计、信访、财政、环保、卫计、公安、纪检、检察、民政、不动产登记、机动车、银行等各行各业的数据进行整合,但出于部门利益、信息安全的考量,实践中“信息孤岛”的情况仍大量存在;
对有限的数据挖掘利用不充分的问题。部分地方已经把干部相关历史数据和在创新管理过程中搜集的重点领域工作表现、邻里风评、个人发展意愿、干部工作日志等信息统一纳入干部大数据之中,却对这些数据的使用局限于简单的统计分析和数据查询;
考核量化指标、分析输出结果的科学性问题。数据虽然不会说谎,但考核量化指标的制定和大数据分析模型却不可避免地会受到人的影响。建设者会自觉不自觉地将自己的固有经验和个人偏好注入考评指标的量化和大数据模型的分析计算中去;
结果运用上的不公开不透明问题。有些地方虽然设计出相应的机制,但是由于这些数据和结果并不公开,仅供有决定权的领导参考,所以没有发挥实质性作用。
同时,全方位掌握干部数据信息确实为分析研判干部情况提供了坚实基础,但数据搜集分析使用过程中的干部个人隐私保护和数据库的整体安全问题也需要引起足够的重视。另一方面,大数据的使用让领导干部成了“透明人”,对作为被管理对象的党员干部个人素质和道德水平提出了更高的要求。而对管理者而言,大数据平台使用不当则可能会沦为政治打击报复的工具,导致人人自危,进而引发政治风险。
6、为什么要引入大数据“选官”
各级干部的选拔任命都有一定的规则和标准,特别是十八大以来,一系列党内法规的密集修订和出台,使领导干部选任工作更加有章可循,也开始趋于公开化和透明化。但是实践中仍然存在很多问题,比如决定者享有很大的自由裁量权,而且决定过程相对封闭,缺乏有效监督,久而久之这些规则标准就成了摆设,约束力不佳;决策过程具有较强的主观性,选人用人凭直觉、靠经验,在一些地方甚至是“说你行你就行,不行也行。说你不行你就不行,行也不行”;还有的地方领导奉行论资排辈定提拔、先来后到定排名。
在这种行为导向下,一些干部不把主要精力放在本职工作上,而是一门心思经营关系,攀龙附凤,结党营私。我们不能寄希望于选任干部的决定者都是道德高尚或高瞻远瞩的人,因此必须通过制度完善或技术创新来优化干部的选拔任命。在考察任命干部过程中引入大数据辅助决策,可以促进选人用人决策科学化、知事识人精准化,让考察任命过程去经验化、去直觉化,最大限度地减少人为干预和决策失误。
毋庸讳言,“大数据选官”的设想和探索还存在诸多问题,但是时代发展和实践需要对干部的选拔任用提出了更高的要求,人民群众不断增强的民主意识也呼唤更加科学、民主的干部选拔方式。
大数据选官一方面利用干部个人信息、考核信息、政绩信息、群众舆论信息以及其他职能部门信息综合研判干部的各方面能力,为干部进行全方位政治画像,建立储备干部库。
另一方面,根据空缺岗位的工作职责和领导班子实际情况,对职位需求进行精准描述。最后对干部的政治画像和岗位需求进行人岗匹配和人事匹配。
与常规干部考察选拔流程相比,大数据选官有着无可比拟的优势:
可以精准的进行岗位需求和个人能力的匹配;
突破人事部门对“候选人范围”所框定的主客观限制,实现跨部门跨地域选拔优秀干部;
用数据说话,评选结果更加客观、全面、准确,彻底改变了以往凭经验和直觉选人的弊端,也排除了选拔过程中的领导指示干预和个人偏见,避免任人唯亲;
选拔过程趋于透明化且有据可循,结果更有说服力。不仅实现了科学、精准的选人用人,而且是以人民群众看得见的方式选拔;
干部管理动态化、可视化,好的干部能露头、慵懒干部可识别,更好地落实了干部能上能下的管理要求。
更重要的是,大数据选官能够体现人民的意志,体现选拔过程的民主性:作为基础数据的舆情信息、群众评价、民主测评和邻里风评就充分体现了民意,干部工作实绩、重点领域和急难险重工作表现等数据则体现了一名干部为人民服务的意愿和工作能力。
结语
十八届四中全会指出,全面推进依法治国是实现国家治理体系和治理能力现代化的重要保证。而干部选拔任用的信息化和科技化是依法治国和实现国家治理体系和治理能力现代化的题中应有之义。数据和算法是“死板”的,“电脑”是铁面无私和客观公允的,但他们都是遵守规则的。因此,让数据和算法代替人脑去适用干部的选任规则和标准可以有效地防范吏政腐败,促进干部选拔任用的科学化和民主化。诚然,“电脑”是人设计的,有关的大数据规则算法也都是人预先制定的,而且,“电脑”缺乏人才选拔所需要的灵活性,其确认的数据有时也需要人为介入进一步调整,但是“电脑”的介入可以保障规则的严格适用,可以有效地防止任人唯亲和买官卖官,也可以促进官员群体行为方式的转变,即从“以关系为本”的行为模式转变为“以规则为本”“以人民为中心”的行为模式,从“唯上”向“唯实”转变。这种转变不仅有利于依法治国,也有利于干部敬业精神的养成。各级干部不再为关系而奔忙应酬,就可以把更多的精力用于本职工作和服务人民,进一步促使干部“向下看”,对党的事业负责,对人民群众负责。当干部们养成“以规则为本”的行为习惯,真正树立起“以人民为中心”的根本立场时,当官员们的道德水平都有很大提升时,当吏政腐败不再是严重问题时,“电脑”们也就可以退休了。
*改编自《大数据“选官”的法理思考》,原文发表于2020年第4期《甘肃政法学院学报》。


扫描二维码
关注我
投稿邮箱:

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}